 |
|||||||||||
|
2012
2010
2009
2008
2007
December 17, 2007.
英語学習のススメ
スルメではない。ススメである。SEには英語が似合う。いい女に深紅の薔薇が似合うのと同じだ。のっけからハードボイルド調な意味がよく分からないが、あまりに固ゆでが過ぎると、喉に詰まらせるので注意したい。かといって半熟過ぎても、とろけ出た黄身で口の周りを火傷したりする。つまり何事も程々という事ではなかろうか。
火傷が酷くならないうちに本題に入る。SEに必須だから英語を勉強している、というと非常に外聞が良いが、実は単なる趣味である。主な目的はTOEICのスコアアップ。それ自体が目的であり、向上した英語力を特に何かの役に立てる予定では無い。黙々とテトリスのハイスコアに挑戦しているのと同じである。しかし電車の中で英語を勉強していると、DSをやっているよりも傍目には奇異に映るらしく、よく見知らぬオジサンに凝視される。別の興味でないことを祈るが。
これまでに洋書を数十冊、辞書無しで読んだ。分からない単語が無かったのではない。速読力を身につけるために、不明箇所を想像で補いながら読んだという意味。確かに効果はあって、830点を取得できたし、「730点レベル」を謳う本はかなり読めるようになった。しかし、レベル表記すら無い本に手を出してみて愕然とした。分からない単語が多すぎるのだ。妄想で補いすぎで、もはや物語を新作している状態である。
そんなわけで、単語力強化と文法の見直しを目的に、ある有名な小説を辞書を引きながら読み始めた。あるトライアルを兼ねることで挫折禁止としている。結果報告は読み終わってからする予定だが、今のペースだと1年近くかかるだろう。
そんなわけで、電車での利用を考え、電子辞書の購入を検討したが、代わりに良いものを見つけた。日ごろPCで利用している英辞郎の辞書データを携帯で閲覧する、AZ(http://ese.s25.xrea.com/az/)というアプリだ。携帯キーによる短縮入力(たとえば、bookを検索する場合、2665と入力すればよい)に対応するなど、非常に優れた設計だ。
しかし使い勝手の悪い点もある。速度が遅い、入力が曖昧なため短い単語を検索した際に候補が多すぎる、和英に対応していない、リンク語へのジャンプができない、字が大きい、などである。ただし、これらは自分の好みの問題であり、アプリの欠点ではない。アプリ自身は非常に素晴らしい。
そこで、辞書検索ソフトを自作してみることにした。とりあえずは英和を作成し、操作方法などを自分好みに作りたい。ある程度のパフォーマンスが出るなら和英にも挑戦してみたいと思う。
【ファイル内検索】
携帯電話で辞書ファイルから単語を検索する方法を考える。自分の持っているバージョンの英辞郎の場合元データは85MB、130万行ぐらいある。頭から順に読むととんでもないことになるので、分割を考える。アルファベットごとの分割も良いが、サイズに偏りが出来るため、サイズ上限を決め、行単位で分割する。
さて、分けた各々のファイルの最後の単語をリスト化しておく。このリストを別ファイルに保管しておき、プログラム起動時にメモリに読み込んでおく。検索時にはまず、検索ワードがどのファイルに含まれるかをリストから探し、該当する分割ファイルから単語を探す。すると、130万行のデータの検索にかかる時間(t)は以下の式で求められる。
t = (ファイル名検索時間) + (ファイル発見時間) + (ファイル内単語検索時間)
ところで、ファイル名の検索時間とファイルの発見時間はファイル数に依存するため、ファイル数をN、ファイル名検索コストをp、ファイル発見コストをqと置くと式は以下のようになる。
t = (p * N) + (q * N) + (ファイル内単語検索時間)
ファイル内の単語検索時間はファイル内の行数に依存する。ファイル内の行数は全行数をファイル数で割ったものなので、130万/Nである。したがって、ファイル内の単語検索コストをrと置くと、上の式は下のようになる。
t = (p * N) + (q * N) + (r * 1300000 / N)
さて、ここで単純化のために、SDメモリが携帯の内部メモリと同じ速度だと仮定し、pもqもrもまぁ、同じぐらいのコストになる、という超大胆な仮定をする。すると上の式は
t = 2N + 1300000/N
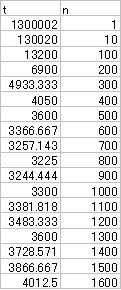
という風に展開可能である。baristaは方程式が苦手で解けないので、EXCELでシミュレーションを行なったところ、だいたい800ファイル程度に分割した場合が一番高速という事になる。
実際にはメモリに読み込んだリスト内の検索やファイル検索は、ファイルを読み込んで1行ずつ処理するよりずっと速いし、ソート済みのデータのため、オンメモリなら二分検索などを利用すれば、さらにpやqのコストは下がる。もっとファイルを細かく分けたほうが高速なはずだ。肝心なのは、ファイル数が200の時と500の時ではコストが2倍程違うこと。それ以降のコストの変化はゆるやかだ。少なくとも4〜500ファイルに分割すべきなことが分かる。無論、携帯端末の仕様上問題が無ければだが。
※パスにはこの日記のタイトルをコピペして下さい。
Copyright 2007 barista. All rights reserved.
| December, 2007 | ||||||
| SUN | MON | TUS | WED | TUR | FRI | SAT |
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 | |||||